| Hadoop Illuminated > Big Data |  |
|---|
| | |
Table of Contents
You probably heard the term Big Data -- it is one of the most hyped terms now. But what exactly is big data?
Big Data is very large, loosely structured data set that defies traditional storage

Human Generated Data is emails, documents, photos and tweets. We are generating this data faster than ever. Just imagine the number of videos uploaded to You Tube and tweets swirling around. This data can be Big Data too.
Machine Generated Data is a new breed of data. This category consists of sensor data, and logs generated by 'machines' such as email logs, click stream logs, etc. Machine generated data is orders of magnitude larger than Human Generated Data.
Before 'Hadoop' was in the scene, the machine generated data was mostly ignored and not captured. It is because dealing with the volume was NOT possible, or NOT cost effective.

Big data is... well... big in size! How much data constitute Big Data is not very clear cut. So lets not get bogged down in that debate. For a small company that is used to dealing with data in gigabytes, 10TB of data would be BIG. However for companies like Facebook and Yahoo, peta bytes is big.
Just the size of big data, makes it impossible (or at least cost prohibitive) to store in traditional storage like databases or conventional filers.
We are talking about cost to store gigabytes of data. Using traditional storage filers can cost a lot of money to store Big Data.
A lot of Big Data is unstructured. For example click stream log data might look like
time stamp, user_id, page, referrer_page
Lack of structure makes relational databases not well suited to store Big Data.
Plus, not many databases can cope with storing billions of rows of data.
Storing Big Data is part of the game. We have to process it to mine intelligence out of it. Traditional storage systems are pretty 'dumb' as in they just store bits -- They don't offer any processing power.
The traditional data processing model has data stored in a 'storage cluster', which is copied over to a 'compute cluster' for processing, and the results are written back to the storage cluster.
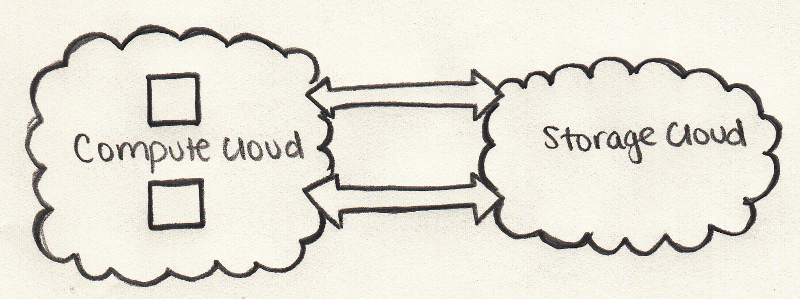
This model however doesn't quite work for Big Data because copying so much data out to a compute cluster might be too time consuming or impossible. So what is the answer?
One solution is to process Big Data 'in place' -- as in a storage cluster doubling as a compute cluster.
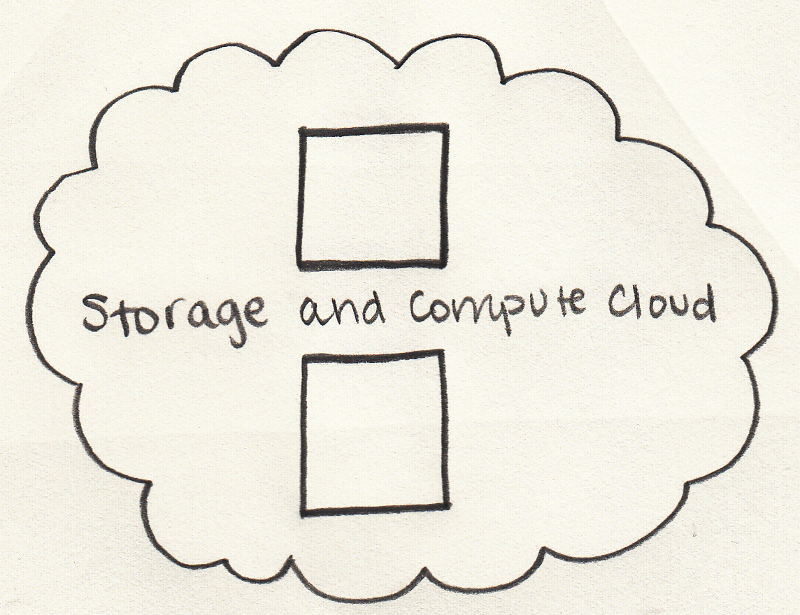
So as we have seen above, Big Data defies traditional storage. So how do we handle Big Data? In the next chapter we will see about Chapter 4, Hadoop and Big Data
| | | |
| Chapter 2. About Authors |  | Chapter 4. Hadoop and Big Data |